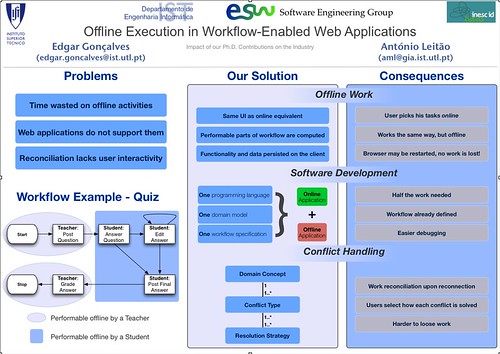
There are two broad strategies for designing smart client communications: service-oriented and data-centric. When you have determined which of these to use, you need to make some fundamental design decisions to allow your smart clients to work offline. In most cases, the clients should be designed to use asynchronous communication and simple network interactions. Clients will need to cache data for use when offline, and you will need a method to handle data and business rule conflicts when the clients go back online.This is a good overview for what I'm going to handle. Microsoft wants its PDA's, and other Smart Clients to be able to perform tasks while disconnected from the server. I want regular Web Applications to the the same, so I'm making the client browser just lie Microsoft's Smart Client. Let's overview their main points:
[From Chapter 4 - Occasionally Connected Smart Clients]
- Approach: MS distinguishes a Data-centric and a Server-oriented approach to disconnected systems. The following graphic (taken from their article) illustrates that while data-centric approaches are not scalable due to their local replication of the entire database, the service-oriented approach also suffers from the lack of business logic (thus relying on the local cache without letting the server know it is not being contacted. We can envision server updates to this interface and/or business logic with painful consequences for the client... My approach is a mix between those two, for I want to design a client that is able to fetch a server module with both UI and business logic, and the necessary data for it to work. However, because we want the application to update the workflow, all client actions will still be postponed to the time that a server is reachable.
.gif)
- Conflict types: I've previously detected that all conflicts aren't the same. In fact, whenever someone edits a previously existing data (e.g., a student changing his email address), there is a simple data conflict, as the information on the client differs from the server's version. But this is a different case from an edition to a already deleted data (e.g., the same student tries to answer a question in a quiz that has already been removed by the teacher). MS article refers to the first case as Data Conflicts, and to the second as Business Rules Conflicts. Note that data conflicts may not be trivial to reconcile - consider a situation where two different entities change the same information, one offline, another online. Both want to change it, only one will succeed at first, but the offline client may need to merge its data, after having it sorted out with the other user.
- Locking mechanism: while a pessimistic approach would minimize all sorts of conflicts, it is obviously not scalable to a widely shared data-set. So with an optimistic approach comes the need to synchronize and reconcile conflicts.
- Reconciliation types: MS assumes the same three locations to do the reconciliation I've detected so far. If the conflict can be automatically merged, it will take place on the server. If not, it may take place on the client (with a simple user interaction dialog), or it may require the launch of another task that will contact other parties (e.g., two students posting the right answer to a question, needing the teacher input to opt for one of them).
The article further discusses CRUD operations as the ideal services to have in these situations (i.e., complex services would make client-side data synchronization harder and harder), and propose some strategies to handle task-based functionality dependencies.
While this is the closer I've read so far to what I want to do for my PhD, it's still lagged behind, as I propose a methodology to adapt existing applications (e.g., pick up existing web services and build from there), and I propose a conflict - and resolution mechanism - description that seamlessly integrates with the remainder application.