I have finally stopped to upgrade my Remember the Milk (RTM) usage to something more GTD-ish (for David Allen’s “Getting Things Done” approach). I already knew about RTM’s organizing abilities. Succinctly, we can have tasks in our inbox, in lists (hard to move from, usability-wise), and have them assigned one or more tags, easily exchangeable and searchable. What I was looking for was a way to have my tasks split into contexts (like calls to make, errands to do, things to do at the computer, things to see, read or listen). Also, I need to see what I can do next, what I have to do someday, and things I must hold on pending, waiting for something/someone. With these two axis for plotting my tasks, I can add stuff to RTM as they come up in my life (via many different ways like their website, Twitter, quicksilver, a Dashboard widget, iPhone...), and they will get placed into Inbox. At the start of the morning, I have to process that list, placing tasks into a proper context List (I prefix those with a @, to visually identify them at a glance). I also tag each task with a “next”, “someday” and “waiting” tag. The final visual output is clean enough for me to feel organized:
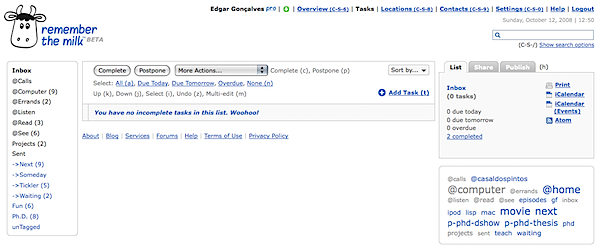
Let’s get the webpage hacks discussed first. It’s simple enough, but important for me. The default tag strip wouldn’t do it for me. So I got this amazing Greasemonkey script, called A Bit Better RTM. Three simple features that make all the difference!
Step one, projects. I followed many advices at the RTM forum, and created a list called Projects, where I place project titles (prefixed by a dot, for visual identification), and tag them with a “p-PROJECTNAME” tag. This way, I can easily click that tag and access all tasks (from one or more contexts). It’s really handy.
Step two, smart lists. These are simply saved searches, and we have a decent set of search operators to use. Here’s some I have installed:
• ->Next: (tag:next AND NOT dueAfter:"1 week of today") OR dueBefore:"1 week of today"
• ->Someday: tag:someday
• ->Waiting: tag:waiting
• ->Tickler: NOT due:never
• PhD: tag:PhD OR tagContains:phd
• Fun: tag:entertainment OR tag:game OR tag:movie OR tag:night
• unTagged: isTagged:false OR (NOT (tagContains:"next" OR tagContains:"someday" OR tagContains:"waiting"))
Tickler is a must see every day, to keep myself from forgetting due tasks. Phd looks for tags like p-phd-thesis, thus looking for all projects related to my Ph.D.. unTagged is a reminder tool. It often happens that I move a task from inbox into a given list, and forget to tag it (all tasks should have a next/someday/waiting tag on it).
Don’t forget that tasks can easily be assigned a priority with a 1-4 key press. Also, I have locations set up so that they appear in the task cloud. This way I can look at all the calls I have to make at the office, for instance.
So with this I feel almost at ease. But I’m kind of a control freak, and I like to add tasks in the easier way I can. After having played with Firefox’s ubiquity to write Twixfer, I started jotting down a quick way to add a task to RTM. The initial ubiquity command was usable, right until it popped up a new tab with a RTM task properties form. I didn’t need that. But someone felt the same, and spared my the effort. rtm-v2 is a command set that logs in, and gives proper feedback of your RTM lists and tasks. If you’re into speed task jotting, it’s worth a try.
That’s my rtm tips for today. Do it like me? Have a better system? Drop me a comment!






